
图书管理系统的开发过程(持续施工中)
不断迭代完善的自用图书管理系统的开发记录点滴。
项目初衷
从高中开始,我开始大量购入图书,于是如何管理它们成为一个棘手而现实的问题。我曾经使用过一些软件和小程序来管理,例如私家书藏和小书房等,但是由于收费(199永久会员纯纯离谱)或者功能不足、被迫下架等原因,都不够让我满意。豆瓣图书本身是个不错的选择,因为它有图书的基本信息和书评。但是它的问题在于只有「想读」/「在读」/「已读」这三个选项,关于「购买」和「阅读」的信息都无法维护。
关于「阅读」,我一直在使用「阅读记录」这款软件,也充值了永远会员。它可以记录每次阅读的时间(时长)以及页数区间等,也能展示一些统计信息。但是它的问题在于缺少「购买」的相关信息,不过用于「阅读」的源数据还是可行的。
因此,我决定开发一个图书管理系统,它可以维护图书的基本信息、购买信息、阅读信息以及一些个性化需求。
V1
在2022年底,由于疫情提前回家,我决定开始开发这个系统。由于我此前并未系统学习过前端开发,因此我没有采用框架。而是直接手撸,Bootstrap 4+JavaScript(jQuery)作为前端,PHP作为后端,数据库使用MySQL。
豆瓣图书信息的爬取是通过一个开源的docker镜像完成的:douban-book-api。
图书的购买信息的获取经历了以下几个步骤:
- python selenium爬虫:京东和拼多多(占total的很大比例,且写起来比较容易)
- 打开网页手动录入订单:当当等小平台(数据很少,没必要写爬虫)、淘宝(有反爬机制,有点麻烦)
- 处理原始数据,手动补全缺失ISBN的部分数据
最后花费小半个月的时间,写了一个几千行的屎山。不过基本功能已经完成,可以正常使用。
功能
主页面,右侧图书每页12本,按照购买时间进行降序排序,左侧为五个主要功能的按钮。(图片已丢失)
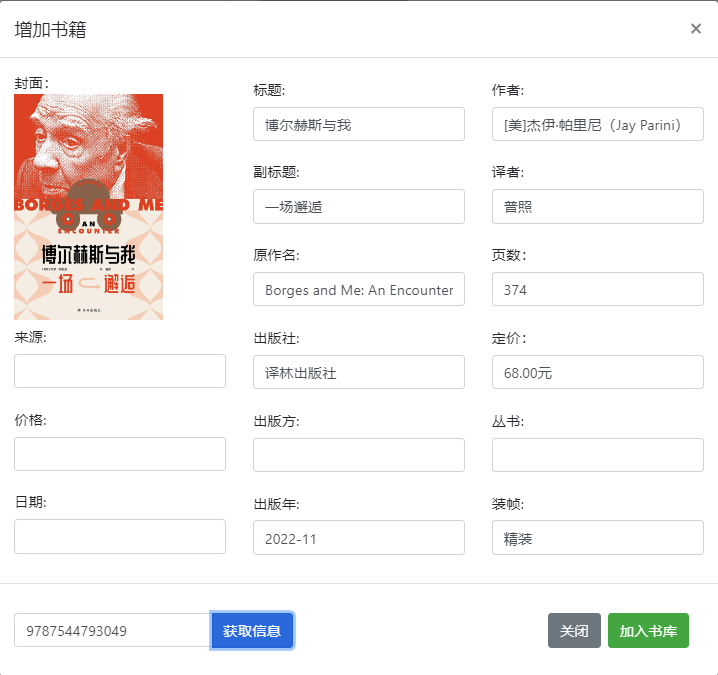
增加书籍,输入ISBN即可获取豆瓣图书的信息,可自行编辑:
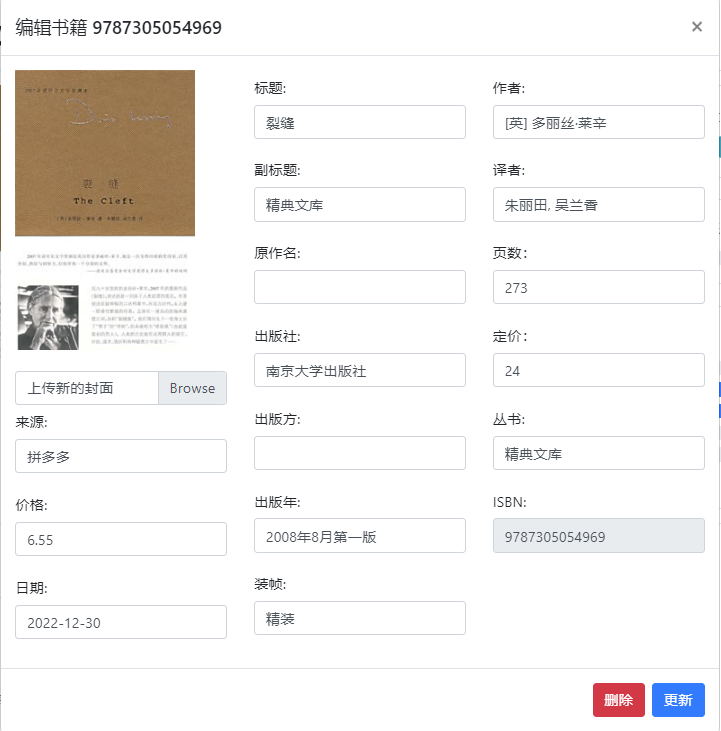
- 编辑书籍,与增加书籍类似,可以自行上传封面或删除图书:
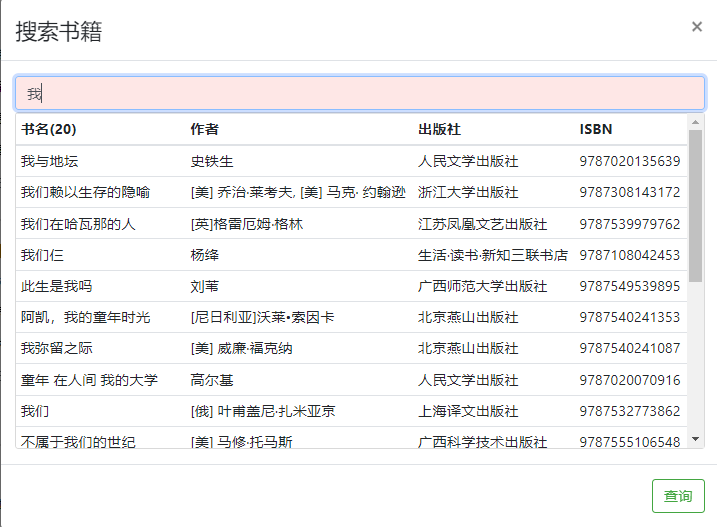
- 搜索书籍,输入关键字可进行实时提示:
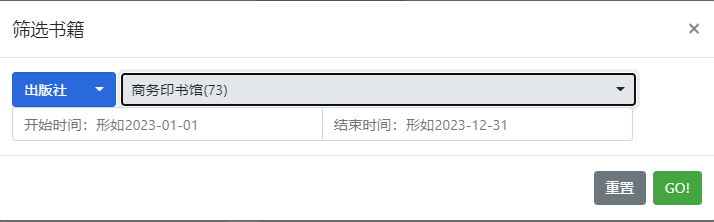
- 筛选书籍,可以根据出版社、出品方和丛书筛选,并可以增加购买时间区间的限制:
- 购买统计数据,主要包括各个平台每月的花费和数量:
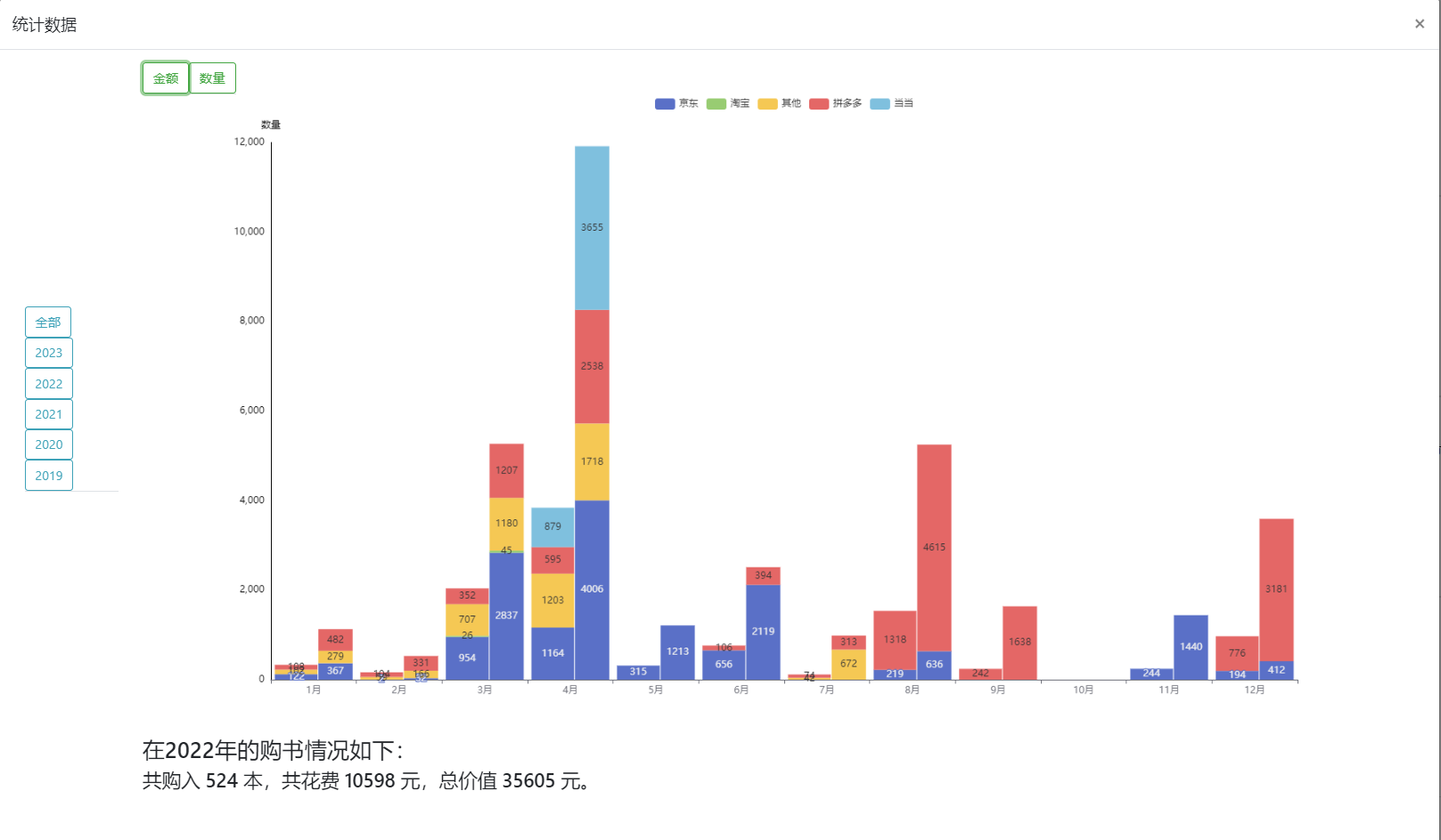
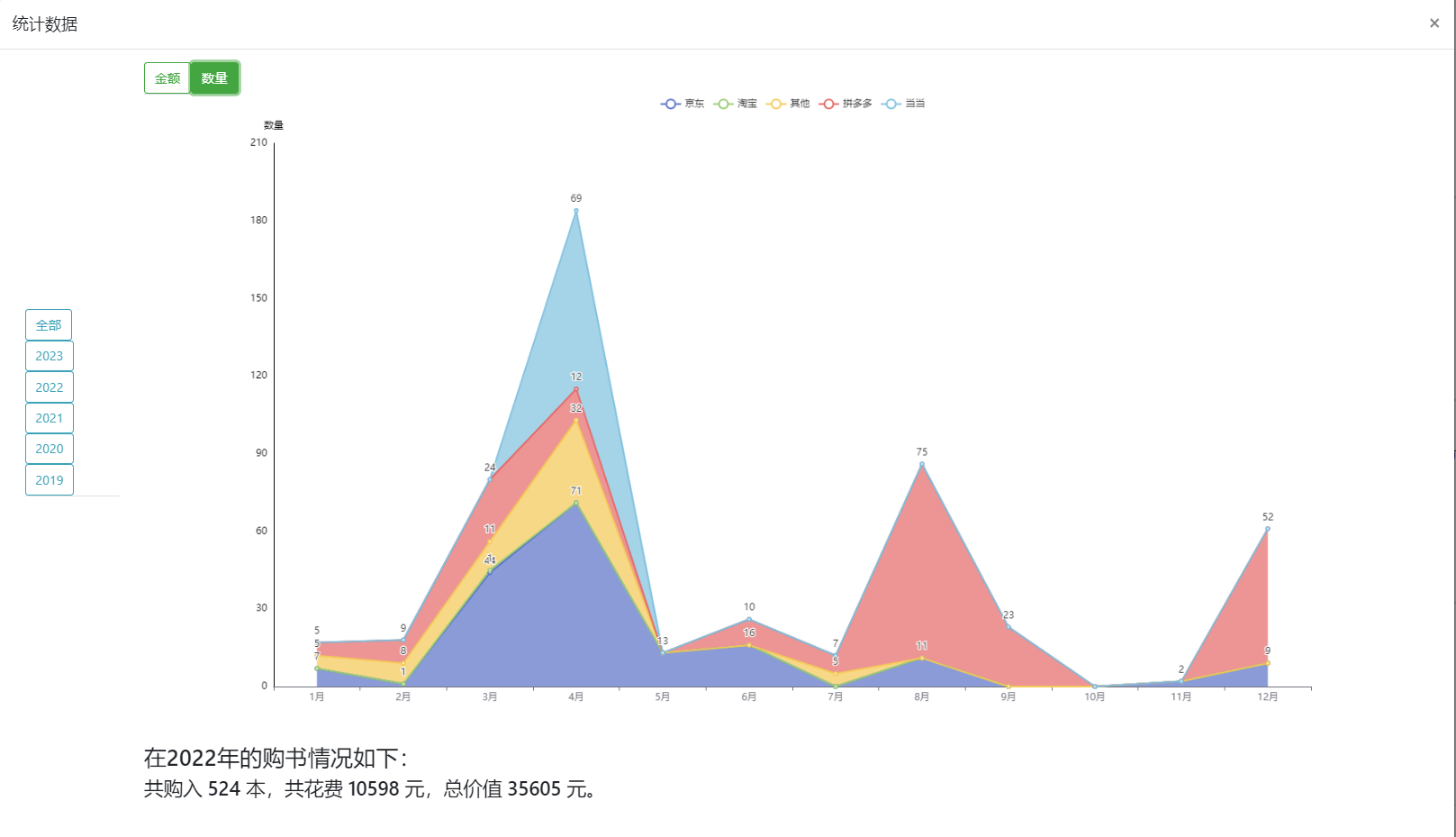
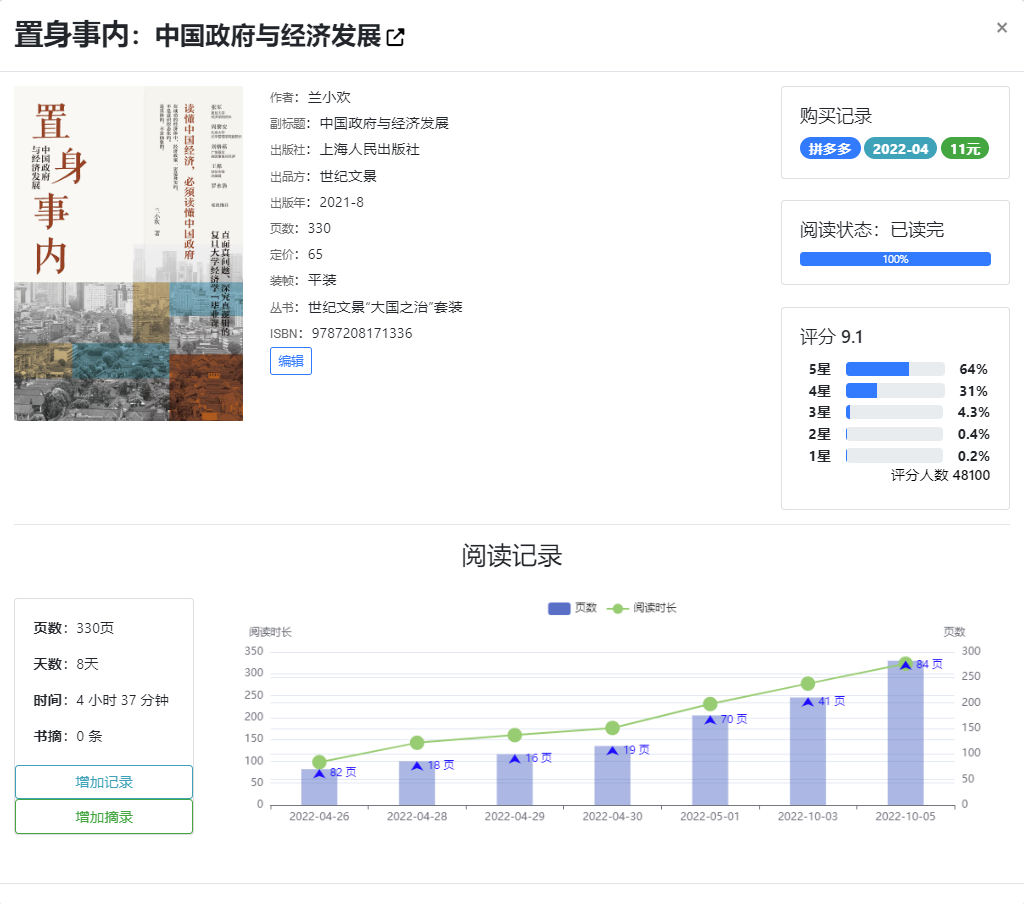
- 书籍详情页,包括图书的具体信息以及阅读记录:
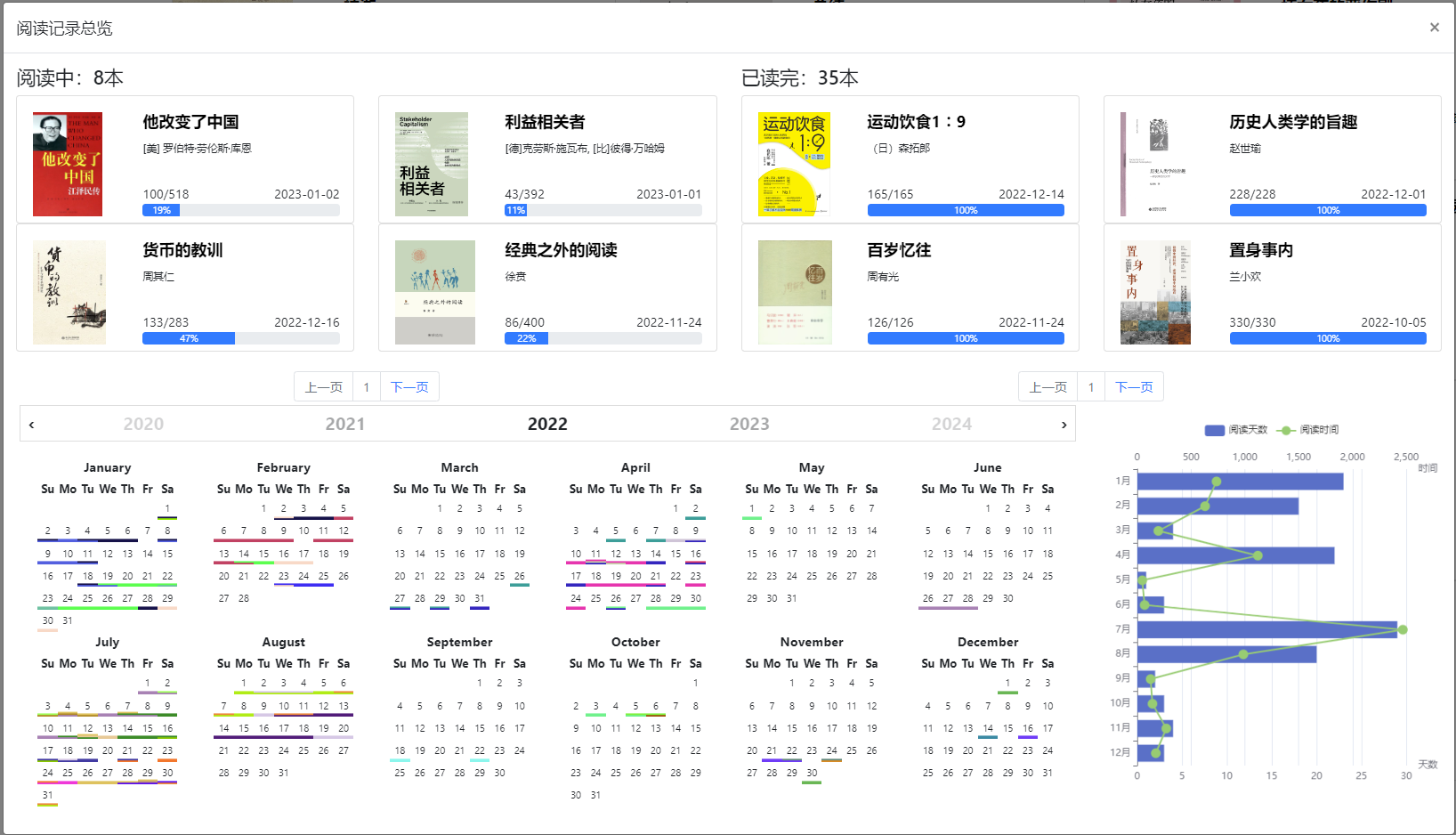
- 阅读日历,包括每天的阅读时长和页数:
结局
为了方便,我选择使用docker配置相关环境并进行开发(dnmp),且没有使用git(容器里没有)。好不容易导入完所有数据,结果在某次重新安装Ubuntu(双系统)的时候,不小心将整个硬盘格式化了。。于是乎,图书管理系统V1暴毙,享年2个月。
V2
半年过去了,到了2023年的暑假。这次我决定先学习一下前端框架,然后重写一个图书管理系统。在听了几十节Vue3+TypeScript的课程后,似懂非懂(啥也不会)的我开始了新的开发。
这次前端采用的是Vue3+Vite+TypeScript+Naive UI,基于一个开源的管理系统qs-admin,后端仍然采用PHP+MySQL。
幸运的是,此前写的爬虫代码和部分数据还在,这加速了我导入数据的进程。
这次仍然是使用dnmp来快速配置环境,不过吃一堑长一智,开始使用git进行版本控制,前后端的代码开源在GitHub上。
功能
主页,显示一些图书的基本信息,可以点击进入详情页

主页 详情页,显示图书的详细信息,包括购买信息和阅读信息
详情页-上 详情页-下 编辑页,可以编辑图书的基本信息、购买信息和阅读信息
编辑页 增加书籍,可以通过输入ISBN或者豆瓣ID来查询图书信息
增加书籍 阅读日历,可以查看每天的阅读时长和页数:
阅读日历 阅读总览,展示已读/正在读的所有书籍
阅读总览 数据总览,以图表形式展示每个月的阅读状态
数据总览 购书记录,以图表形式展示每个月的图书购买状态
购书记录 轮播图,随机展示已读完的图书信息
轮播图










展望
感觉基本功能上已经大差不差了,还是先多读书吧,新需求会自然产生的……